
2. 社会調査を取り巻く研究環境の変化
(1) 伝統的な社会調査
社会調査とは、社会の実態を経験的に把握することを目的に行なわれる調査の総称で、面接でのインタビューや質問票を用いたアンケートによる手法が代表的である。他にも、フィールドワークなどで収集した文献資料の内容を分析したり(ドキュメント分析)、調査対象である集団の一員となり内部から観察したり(参与観察)する方法などがあり、人文学や社会科学の諸研究分野(経済学、社会学、心理学、経営学など)における伝統的なアプローチとして確立され幅広く使われてきた。
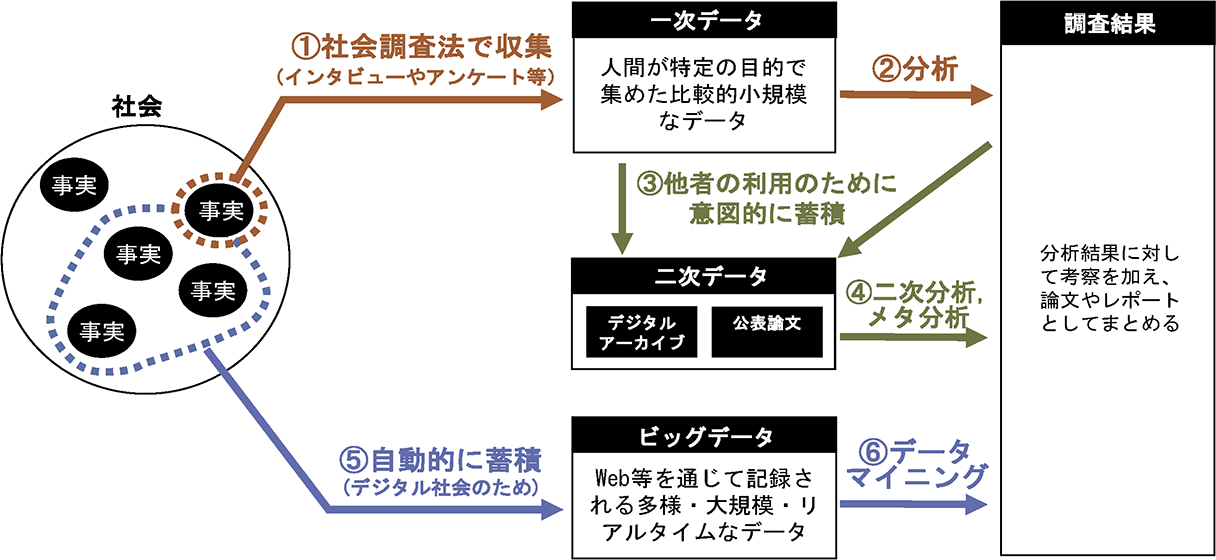
こうしたいわゆる伝統的な社会調査の研究は、大きく分けて2つの段階で進められる(図1)。第一に社会事象の持つ事実を捉えるためにデータ(数値、文字、音声、画像など)を集める段階(図1の①)、第二に集めたデータを分析する段階(図1の②)である。つまり、伝統的な社会調査は、調査者(または組織)が自らの関心や目的のもとで独自に行うデータ収集とその分析からなり、一次的かつ主体的な調査であることや扱われるデータが比較的小規模であることが特徴である。
(2) 新たなデータサイエンスの潮流
ところが、情報通信技術(Information and Communication Technology: ICT)や人工知能(Artificial Intelligence: AI)が急速に発達することで、社会調査のデータ収集とその分析手法のあり方が変容しつつある。この変化は、大きく分けて、既存の社会調査の二次利用とビッグデータの活用に分けることができる。
前者の社会調査の二次利用についての代表例のひとつは、他者が調査・収集したデータを利用した分析(二次分析)である(図1の③および④)。1990年代以降に本格化した情報化の進展に伴い、様々な調査者により実施された社会調査の個票データ(集計前の個人レベルのデータ)を電子資料(デジタルアーカイブ)として長期保存し二次利用できるようにする試みが進んだ1)。社会科学の調査データを収集し1998年から提供しているSSJデータアーカイブなどがある(佐藤ら(2000))。こうした取り組みにより、二次利用できるデータが主に一部の政府統計に限られていた頃から大幅に広がった。
また、社会調査の二次利用には、社会調査の分析結果をまとめた論文や書籍などを多数収集して系統的整理や俯瞰的分析を行う方法(メタ分析)も含まれる。メタ分析に使われる代表的な検索エンジンには、英語論文の検索と被引用回数の表示をはじめ多様な機能を備えたWeb of Scienceや日本語論文を検索できるJ-STAGEが挙げられる。インターネットの普及と発達によって、こうした分析の精度が向上するとともに身近なものになった。
後者のビッグデータの活用は、より最近(2010年頃)になって注目され始めた。ここでビッグデータの定義は、異なる識者の著述の間で様々なものが存在するものの、量(Volume)の膨大性、速度(Velocity)の高速性、種類(Variety)の多様性という3つの性質を持つデータであるという点についてはある程度のコンセンサスがある(Beyer and Laney (2012); Callegaro and Yang (2018))。ネット通販の購入履歴、SNSに投稿された画像、防犯カメラの映像などの多様なデータが、ネットワークの高速化によってほぼリアルタイムで流通し、大容量のストレージなどに自動的に大量蓄積されるようになった(図1の⑤)。そうしたビッグデータの中から有益な情報を掘り起こす分析はデータマイニングと呼ばれ、機械学習を始めとしたAIの応用によって大きく進歩すると同時に、今後の発展がさらに期待されている(図1の⑥)。
(3) 新旧アプローチの代替性と補完性
二次データやビッグデータを用いた分析は、従来の社会調査でアプローチできなかった事実にアプローチできる可能性を持つことから実際に大きな可能性があると考えられる。また、インタビューやアンケートに必要な経費や労力が不要であることから、効率的にデータ収集できる側面があり、従来の社会調査の一部を代替しうる。実際に、世界各国の公的統計におけるデータ収集において、古典的な社会調査に基づくセンサスから行政データの利用へと移行する傾向にあることが指摘されている(Baker(2017))。
他方、そうした新たなアプローチは、従来の社会調査と相互補完的な側面もある。利用可能な二次データの中には目的に適うデータが無いかもしれず、ビッグデータについても社会生活を営む人々の考えや行動の全てがデジタル化され蓄積されているわけではない。また、一般にビッグデータには大きなノイズが含まれており、データの質は社会調査データの方が優れている(Callegaro and Yang(2018))。社会調査データやビッグデータを対比して、両者の代替性や補完性を論じた研究は過去にも存在する。例えば、金融分野には、クレジットカードの利用に関するアンケート調査データの代わりに信用情報のビッグデータを用いても特定の条件のもとで類似の推定結果が得られることを示し、両データの意義を考察した研究がある(Whitaker(2018))。しかし、水産分野の市場データを対象とした考察は、筆者の知る限り見当たらない。以下では、2つの研究を紹介すると同時に、新旧アプローチの意義の観点から考察を行う。
- 1) このような二次データは典型的なビッグデータの定義(後述)とは異なるものの、比較的大規模な複数の二次データを統合することで、さらに大きなデータセットを構築することによって、潜在的にビッグデータに近いデータセット(スモール・ビッグデータ)となりうるという議論もなされている(Gray et al. (2015))。